Dr. Lingzi Hong
Human-Centered Computing Lab
Research Focus
Human-Centered NLP focuses on developing language technologies align with human communication needs and contexts. We integrate insights from human-computer interaction, cognitive science, and social sciences to develop NLP models and create systems that comunicate naturally and adapt to the need of diverse populations in different social settings.
Human-AI Collaboration investigates how intelligent systems and humans work together effectively to enhance problem-solving, decision-making, and creativity. We design interactive and human-in-the-loop frameworks and workflows to ensure the responsible and reliable use of AI in real-world contexts.
Human Sensing for System Design investigates how intelligent systems and humans work together effectively to enhance problem-solving, decision-making, and creativity. We design interactive and human-in-the-loop frameworks and workflows to ensure the responsible and reliable use of AI in real-world contexts.
Grants
Inclusive Services to Enhance Immigrants' Resilience to Crisis
Funded by the IMLS National Leadership Grants: LG-256661-OLS-24 (NLGL: $415,366, PI:Lingzi Hong, Co-PI: Ana Roeschley, Yunfei Du)
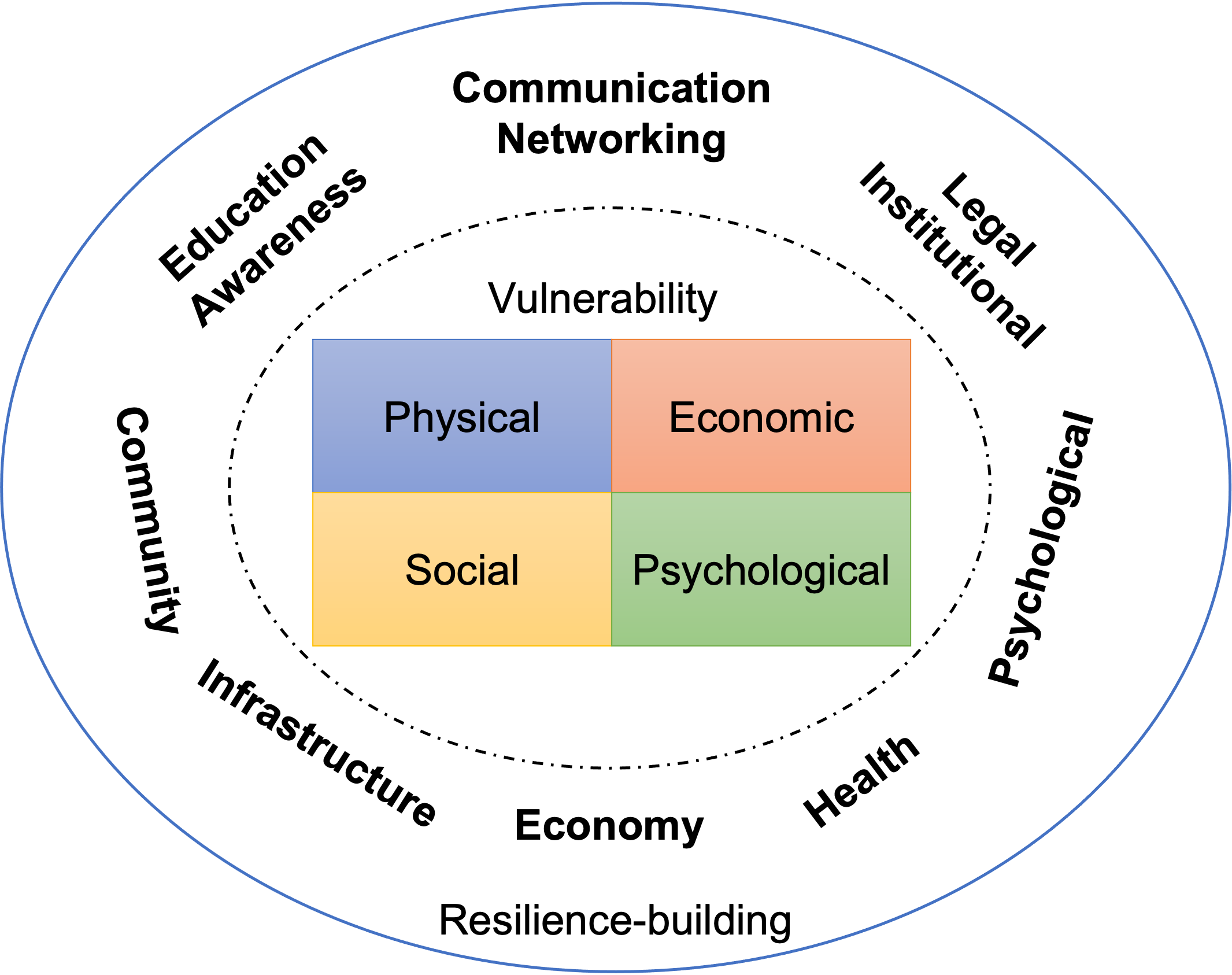
Crisis events disrupt the normal functioning of individuals, groups, or systems, and can result in damaging impacts in various scenarios, including natural disasters, public health emergencies, and economic collapses. They present significant challenges or threats to the safety and well-being of individuals and can strain resources and exacerbate inequalities.
The project will identify the most in-need US counties with high immigrant ratios, high crisis risks, and low resources, which will be the study areas to investigate: RQ1: What are the information needs of immigrants in crisis in under-resourced communities? RQ2: What is the status of public services for immigrants in crisis?
Gauging Library Needs for Advanced AI-Assisted Cataloging
Funded by the IMLS National Leadership Grants: LG-256666-OLS-24 (NLGL: $132,759, PI:Lingzi Hong, Co-PI: Jason Thomale)
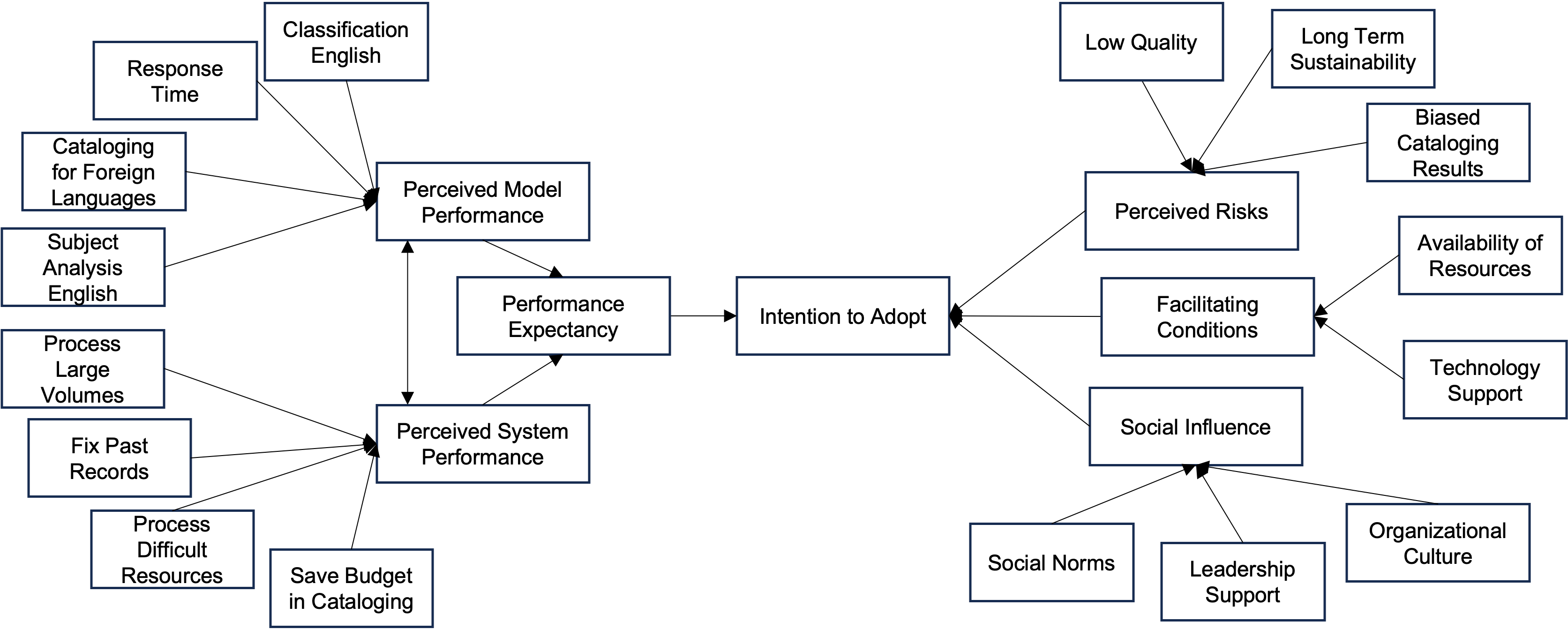
The rapid development of artificial intelligence (AI) has brought about significant advancements in CV and NLP. However, the application of these technologies in traditional domains and their acceptance by users often require extended periods of time. We seek to explore the factors influencing user acceptance of specific AI applications and identify the key issues that should be considered for their successful implementation.
This project will conduct experiments to identify the performance of LLMs in traditional cataloging tasks. Then, we will conduct user studies based on the conceptual framework to identify the factors relevant to librarians' acceptance of LLM in assisting cataloging. We will also conduct interactive user designs to identify how LLMs can be applied to assist librarians.
Data Literacy Needs and Scale Development
Funded by the IMLS Laura Bush 21st Century Librarian Program: Phase 1: Student Data Literacy Needs in Community Colleges: Perceptions of Librarians, Students, and FacultyRE-252374-OLS-22 (Laura Bush: $118,996,PI: Jeonghyun Kim, Co-PI: Lingzi Hong, Sarah Evans), and RE-256673-OLS-24 (Laura Bush: $249,998, PI:Jeonghyun Kim, Co-PI: Lingzi Hong, Brady Lund)
Phase 1 project focuses on examining the perspectives of community college librarians, faculty, and students regarding data literacy. This phase seeks to identify the specific data literacy competencies required for student success, laying a foundation for informed strategies to address these needs effectively.
Phase 2 project aims to position community college librarians as key leaders in data literacy education. Through training, resources, and collaboration, this phase equips librarians to foster data literacy success among students, strengthening library capacity as a cornerstone of institutional support.